Determining the Uncertainty Associated with RAPM
Putting a number on the vapid “limitations” I tell people to consider.
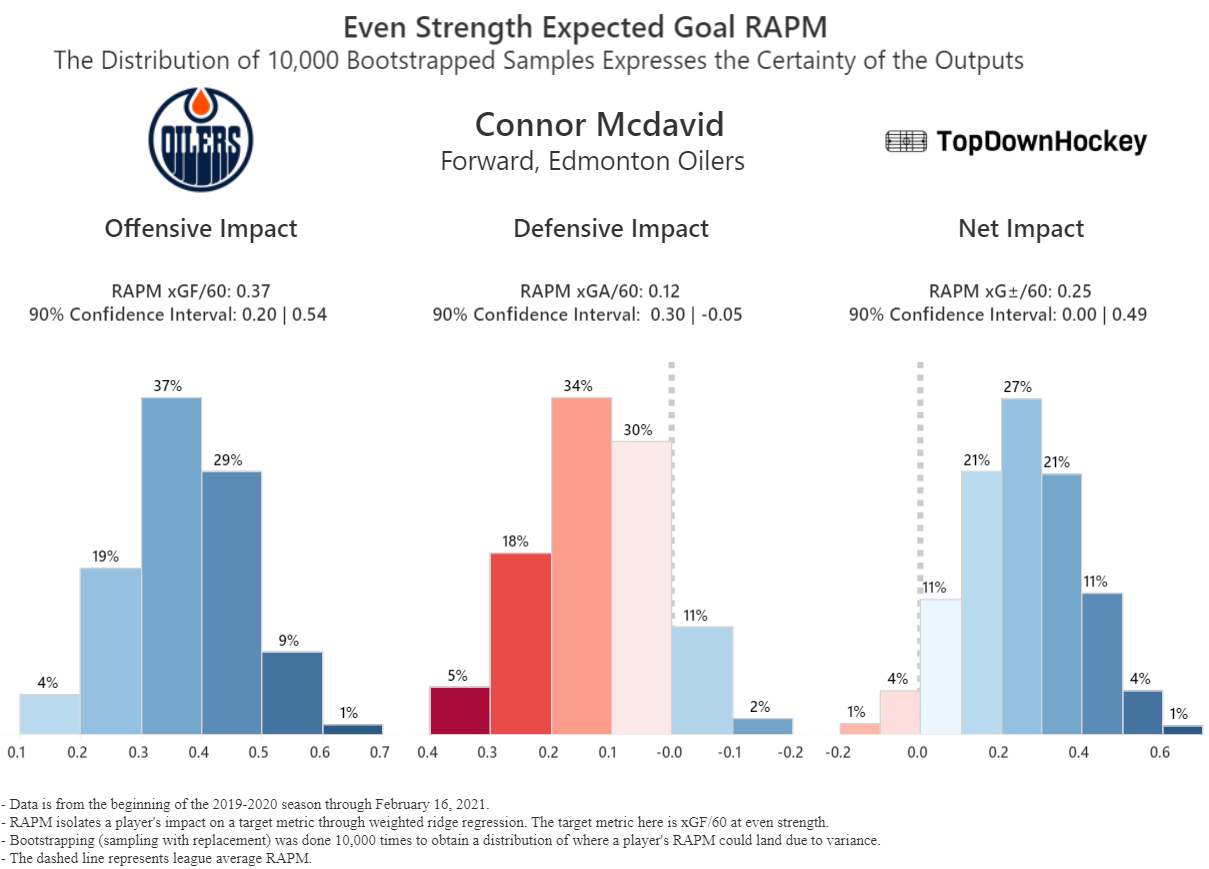
Six days ago, I released What to Make of Paul Maurice’s Crusade Against Public Hockey Analytics?, an article in which I scrutinized various comments Winnipeg’s bench boss made about hockey analytics. I came to the conclusion that outside of a bad faith deflection he made in a defense of his captain, he was mostly right about everything he said, and he also offered some valuable insight into proprietary analytics and solid advice for the public crowd.
If you haven’t already read the article, I recommend you do. Not only is it my best work so far, but it’ll give you a better idea of why I went to the trouble to do what I did here. You don’t have to read it if you don’t want to, but in that case, you should note these key takeaways from it:
- The Winnipeg Jets have five full-time employees working on analytics, and Maurice describes their approach as “full in on analytics.”
- They also have access to proprietary data which is more accurate and granular than the notoriously inaccurate data the public uses, and their expected goals model is roughly 6–10% more accurate than public models.
- Despite this, Maurice still feels they don’t come out of their analysis with the confidence in their opinions that public analytics users do; he advises those users to be a little bit more reserved in the strength of their opinions.
I whole-heartedly agree that we should be more reserved in the strength of our opinions. But just how reserved should we be? That’s a lot trickier to answer, and without a number to put on it, it’s easy to forget to apply any reservations at all. The three most popular analytical hockey models available to the public are probably Micah McCurdy’s Magnus IV, Evolving Hockey’s Regularized Adjusted Plus-Minus, and Dom Luszczyszyn’s Game Score Value Added; none of which provide any sort of confidence intervals, error bounds, or estimates of how certain we can be about the outputs of the models. I’m not slamming these guys for not putting out this information, and I’d be a massive hypocrite if I did, since I didn’t provide any sort of error bounds either when I put out my Wins Above Replacement model a few months ago.
One big reason I didn’t add any error bounds, and that McCurdy and Evolving Hockey don’t, is that although we use regression analysis, the type of regression we use is a ridge regression, in which coefficients are shrunk towards zero and therefore standard errors are not obtained. Luszczyszyn’s model is a bit different, and is built mostly on box stats instead, which doesn’t exactly lend itself to error bounds either; if a guy had a goal and two assists, he had a goal and two assists — no less and no more. Obtaining and reporting confidence intervals for all these models is difficult, and most fans understandably aren’t too interested in squinting at error bars for hours on end, so it makes sense that they’re generally not reported alongside public hockey analytics models.
But, in order to remind everybody that these error bars do exist, and to provide an idea of just how big they are to both the public and myself, I decided to obtain them through the alternative method best used for obtaining confidence intervals in a situation like this: Bootstrapping.
To explain what bootstrapping, I’m going to do what every good data scientist must do at least once in their life and make an example out of the mtcars dataset from R. This is a very small, simple data set which contains various information about cars like miles per gallon, cylinders, displacement, horsepower, rear axle ratio (drat), and weight. Here’s a snippet of the data, sorted by miles per gallon and showing all the columns I’m going to use (and a few I won’t):

If I run a linear regression using weight and displacement as predictor variables and miles per gallon as the target variable, these are the coefficient estimates and standard errors I receive:

The coefficient estimate plus or minus one standard error can be interpreted as the 68.2% confidence interval. In other words, we can be confident that within the “true” distribution, there is a 15.9% chance that the coefficient estimate is 1 standard error below the estimate we received, a corresponding 15.9% chance that it is 1 higher, and a 68.2% chance it falls somewhere between the coefficient plus or minus one standard error. From this, we can infer the following values:
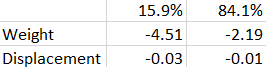
In other words, we are 84.1% confident that within the “true” distribution, the correlation between weight and miles per gallon is greater than -4.51, 84.1% confident that it is lower than -2.19, and 68.2% confident it’s in between the two. Put more simply, weight has a significant negative correlation with a decent sized error, while displacement has a small negative correlation that can maybe just be chalked up to variance.
What if I didn’t have these standard errors, though, and had to get them? This would make it time to pull myself up by the bootstraps, as the saying goes, and make something out of nothing using the aptly named statistical technique: Bootstrapping. The way this process works is I pull a sample from the data that’s the same size as the original data (32 rows in this case), but I randomly remove some rows and randomly duplicate others.
Here’s a snippet of one random bootstrapped sample from the same data:
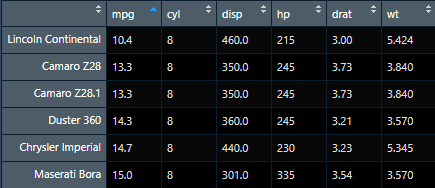
This looks very similar to the first snippet I showed with one key twist: Cadillac Fleetwood is missing and replaced by a duplicate of Camaro Z28. The bootstrapped sample still has 32 rows, but some are entirely missing, and a separate duplicate of another row exists in place of them. (Some rows can be duplicated more than once; the sampling process is completely random and pays no attention to what has already been sampled.) If I run a regression using the same target and predictor variables on this bootstrapped sample, I get similar but not entirely equal results:
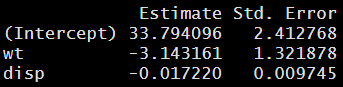
I repeated this process with 10,000 different bootstrapped samples and then looked at the distribution of the coefficient estimates in every single one of them. Here are the values that I found at the 15.9th percentile, 50th percentile (center) and 84.1st percentile for the distribution:
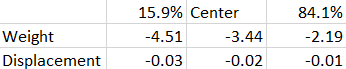
These values are pretty much identical to those inferred from the standard errors and coefficient estimates from the true regression. This validates the bootstrapping process and tells me it’s sufficient for use in the absence of “true” standard errors.
Now, back to hockey: I used all data from even strength for the 2019–2020 season and all data at even strength from the 2021 season up to February 16, 2021. While this is not technically data from one full 82 game season, it’s still extremely similar; there are roughly the same number of shifts, shots, and goals, and the Lambda selected through cross validation (which can be interpreted as the degree of uncertainty most optimal to apply to the data) was basically identical to that of the 2018–2019 season. The more mathematically robust way to do this would probably be to use the 2018–2019 season instead, but I’m ultimately doing this for fun, and I thought it would be a lot more fun to do something with the 2021 season, my shiny new toy. (I also wanted to use data others would find relevant and interesting.)
As I made my switch from the mtcars dataset, I switched over from a data set with 32 columns and 11 rows — only 3 of which I used — to a data set with roughly 600,000 rows and 1,900 columns. And, as I mentioned, I didn’t run a standard linear regression, but rather a weighted ridge regression where shift lengths were used as weights and coefficients were shrunk towards zero in order to handle multicollinearity and players who played small samples. (If you’re interested in learning more about this process, you should take my comprehensive guide to using regression to evaluate NHL skaters which includes source code.)
Although I made these changes, the bootstrapping methodology remained valid and the process the same: I randomly sampled the roughly 600,000 shifts with replacement and ran the regression with a new bootstrapped sample 10,000 times. I obtained the coefficients from each regression, which can be interpreted as the isolated impact that each skater has on the target variable (xGF/60) and stored these for each player for the 10,000 samples.
For the results, I’ve chosen to exclude players who haven’t played at least 500 minutes at even strength. This is an arbitrary threshold I threw out there, but I think most of us have a good idea that we shouldn’t be making confident statements about players who haven’t even met this threshold, so I don’t want to throw them in here and skew the data, but I also don’t want to shrink the sample even further and reduce the variance. There are 578 players who met this threshold: 211 defensemen and 367 forwards.
I’ve chosen to express these results in the form of the percentage of players whose lower and upper bounds were either both above or both below average within a given confidence interval for each metric. In other words, within a given confidence interval, what percentage of skaters can we state were above or below average? Here’s the answer:

The proof is in the pudding here; even at the 68.1% confidence interval, for most players who played 500 minutes, we can’t make a confident statement that their play driving was above or below average. If we want to be 90% or 95% confident in our statements, these numbers plummet quickly.
It should also be noted that all this research and every conclusion I’ve drawn here is done under the premise that the data within the sample is 100% accurate. Unfortunately, that isn’t entirely the case either; we know that the play-by-play data is notoriously inaccurate and missing key context, and that public expected goal models are far from perfect, so that adds some additional uncertainty to the data. For example, I may say that there’s roughly a 44% chance that Patrick Kane’s offensive impact is positive. But with a more accurate expected goal model that incorporates some key information that changes my model’s interpretation of what happens with him on the ice, that number would likely be well over 50%.
The test that I just completed was a test to determine how much confidence we can place in the descriptive power of RAPM. This is but one way to look at things and determine how strong the reservations that we apply to our conclusions should be. Another way is to test the predictive power by looking at how repeatable the metric is. In order to test this, I opted for a different approach, and used even strength expected goal RAPM from 2013–2014 through 2018–2019 — the last 6 full seasons that have been played — and tested the correlation between year 1 and year 2 for forwards and defensemen who played at least 500 minutes at even strength in both years. Here are the R² values for each metric:
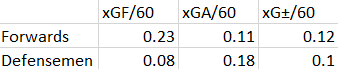
Not only is there a good deal of uncertainty that should be applied to how well RAPM actually measures a player’s impact in a given year, but our measurement in year 1 doesn’t manage to explain a huge percentage of the variance in our measurement in year 2.
I must note, before I conclude, that even on the stat sheet, there’s more to a player than their even strength expected goal RAPM. Other things like shooting talent, special teams impacts, and penalty impacts are important as well, and once these important factors are taken into consideration alongside a prior-informed RAPM with very similar methodology to build Wins above Replacement, plugging WAR/60 from year 1 into TOI in year 2 and using projected WAR to predict goal differential gives a much stronger R² value than any of the values shown here:

While this R² is not excellent, it does show that these metrics can be built out in a fashion that is predictive of future events, and that the R² values shown above for the repeatability of RAPM are a bit unflattering. These metrics aren’t completely blind to predicting future events; they’re just not quite as good as we may want to believe they are when our favorite team signs a player with good RAPM or our favorite team’s rival signs somebody with bad RAPM.
What do I make of this humbling reality check? I think it’s awesome. It tells us that while we’ve come far, we’ve still got a long way to go and a ton of improvements to make. Our methods are very far from perfect. I’m also open to seeing anybody else try a similar process, either in terms of expressing the uncertainty of the descriptive power of their models, the predictive power, or both. My model isn’t the only one out there, so it’s possible somebody else with the secret sauce has data that we can have more confidence in.
However, I doubt anybody — even NHL teams with access to proprietary data and full analytics staffs — has a model that does a far better job at either of these things and doesn’t come out with some fairly large error bounds. This is because, as much as it’s a tired cliche we hear from the anti-analytics crowd, hockey isn’t baseball. To express what I mean here, let me first quote Billy Beane’s character in Moneyball:
“Guys, you’re still trying to replace Giambi. I told you we can’t do it, and we can’t do it. Now, what we might be able to do is re-create him. Re-create him in the aggregate.”
The fact that this is an iconic baseball quote speaks volumes about the differences between the two sports to me, because you simply can’t do this in hockey! Factors like chemistry, usage, and sheer luck play a much larger role in the performance of a hockey player than they do in the performance of a baseball player.
Say, for example, I had a Wins Above Replacement model that told me that Jonathan Cheechoo was one of the best players in the league in the 2005–2006 season playing alongside Joe Thornton, contributing a total of 4 WAR which was good for 10th in the NHL. If I were a team who lacked a playmaking center and needed to add 4 wins in order to make the playoffs, I would be dumb as hell to try and add Cheechoo to make up those wins even if I trusted the model, because I wouldn’t expect him to individually make the same kind of contribution without an elite playmaking center. This kind of thinking makes sense and leads to success in baseball because player performance is a more individual concept that’s not as interdependent on moving parts, but in hockey.
In hockey, it’s just not the same. Even if you did have a player’s true isolated impact, you’d have to acknowledge that was influenced by chemistry and role at the very least. But, the concept of chemistry alone makes it pretty much impossible to truly isolate impact. So, while hockey models will slowly continue to become better and more advanced, I don’t think anybody will ever be able to build a model that is as effective as today’s baseball models are at telling us how good a player was yesterday or how good they will be tomorrow. I’m going to try like hell to do it, but I doubt it ever happens.
I’ve made peace with this realization. Hockey is just a different sport. If I wanted a sport where models were close to perfect, I’d be a baseball fan. But I’m a hockey fan. If you’re a hockey fan too, I think you should embrace this uncertainty.
To give an example of embracing uncertainty, if somebody brings up Victor Mete and asks to discuss his play driving at even strength since the start of the 2019–2020 season, I’m not going to look at the data and say “he’s a little below average offensively, a little above average defensively, and about average as a result.” Instead, I’m going to look at the data and say “We can be about 80% confident that he’s below average offensively and 85% confident that he makes up for it with strong defensive play, but really only 10% confident that his impact is significant at either end. As a result, there’s a fairly wide range of what his true impact could be, but it doesn’t seem like he’s a major net positive or net negative.”
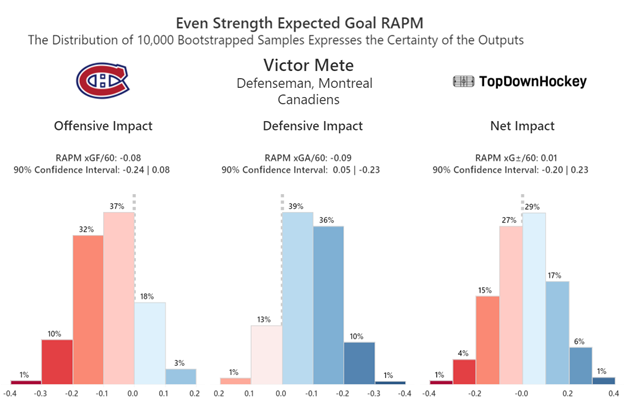
Then, if somebody asks me about trading for him, I’m going to mention that while neither metric is extremely predictive of future performance, the defensive side of RAPM is far more repeatable for defensemen than offense is, so we can probably expect more of that going forward. From there I might also dive into the game tape, and suggest that maybe his poor offensive impact is due to him being miscast; he’s an excellent skater who seems best suited to be the primary puck handler and rusher on his pairing, but Montreal hasn’t recently allowed him the freedom to do so, and he doesn’t appear to be comfortable playing more cautiously in a support role with another puck handler. Assuming his offensive impact truly is negative, this may be the cause, rather than a deficiency in his ability to play offense.
I’ll stop there, because while he’s a fascinating player, this isn’t meant to be a Victor Mete breakdown — Jfresh has done a more in-depth version of that if you’re interested — but rather an example of how accepting this uncertainty allows us to make more interesting assessments about players. Not only can we use this uncertainty to have more fun than just posting a chart and calling it a day, but more importantly, we can utilize this uncertainty to be wrong about hockey less frequently.
If you’re interested in seeing the results of bootstrapped RAPM for any player who has played at least 500 minutes and getting an idea of how certain you can be about their impact, the data is available on my Tableau: 2019–2021 RAPM With Certainty Levels — Patrick Bacon | Tableau Public. (Note that I am updating that dashboard as new data becomes available, so the data there will not be exactly the same as it is in this article.)
Lastly, the work done in this article was inspired by and would not have been possible without Sam Forstner’s excellent Reframing RAPM article. His piece has been unfortunately taken down, but Sam took a very similar approach to mine: Bootstrapping RAPM to obtain confidence intervals, and using the results to make the argument that we should be a bit more reserved about the conclusions we draw from this data.
