What to Make of Paul Maurice’s Crusade Against Public Hockey Analytics?
The 6th Winningest Coach in NHL History has Some Good Things to Say.
Suppose that 16 months ago, I told an analytically-inclined hockey fan that over the next 16 months, one man would offer more insight into proprietary NHL analytics than anybody else has over the past half-decade or so. Then, say I followed that up by asking them to guess who. They may guess Eric Tulsky or Sam Ventura, two early pioneers of hockey analytics who are respectively employed by the Carolina Hurricanes and Pittsburgh Penguins, and who earned job promotions in that time frame. Or they may guess Toronto Maple Leafs GM Kyle Dubas who has been branded “The Analytics GM” by both naysayers and fans despite never publishing any work on hockey analytics and working his way up to his position through a rather traditional career ladder for a hockey man.
These would’ve been good guesses, but they’d all be wrong. While Tulsky and Ventura have offered some insight into proprietary analytics through mediums such as Tulsky’s Reddit AMA and Ventura’s Sportsnet interview — both of which I recommend you read if you’re interested in learning more about hockey analytics — nobody has offered more insight into proprietary NHL analytics than Winnipeg Jets Head Coach Paul Maurice. And it’s not even close.
Some credit for Maurice offering this insight is owed to media members like Scott Billeck of the Winnipeg Sun who make concerted efforts to ask, in good faith, the types of questions that will elicit a good-natured response from Maurice. The earliest documentation of this ongoing discourse between Maurice and Winnipeg media that I can find is from November 30th, 2019, when Billeck asked Maurice about expected goals and possession numbers, and how his team didn’t shine in either, yet were still battling for the top spot in the division. Here’s what Maurice had to say:
“Our expected goals model is different than what’s publicly available. It’s accurate to about 85%, so we like it better. Fairly accurate. We like our game.”
This may not sound like a lot of information, but it is. My interpretation of his quote is that the “85% accurate” figure he references is interchangeable with an area under curve (AUC) value of 0.85 — I’ve seen many people use this term this way in the past. By comparison, public expected goal models tend to hover around 0.76–0.8 AUC (mine is currently at 0.785 at all situations and 0.797 at even strength for the 2021 season). So, if Maurice is indeed telling us that Winnipeg’s expected goal model has an AUC of 0.85, this means that due to some combination of the notorious inaccuracy of the NHL’s play-by-play (PBP) data that expected goal models are built on, external factors like pre-shot movement and screens that aren’t incorporated by this PBP data, and modeling techniques used by Winnipeg’s data team, proprietary expected goal models have an AUC that’s roughly 0.05–0.09 higher than those of public models. There is immense value in knowing what we don’t know, and we stand to be wrong about hockey a lot less frequently if we know roughly how inaccurate the shortcomings of our data sources and modeling techniques lead our expected goal models to be.
Uncertainty isn’t sexy, though, and it doesn’t sell. And the public hockey analytics community doesn’t love the idea that somebody knows something they don’t about stats. So, despite providing us with some very valuable information, this quote didn’t gain much traction, and those who did engage with it mostly berated Maurice for not sharing their opinion and citing proprietary data to defend his team. But make no mistake: This is very interesting and valuable information. And based on some other numbers I’ve seen, the 0.85 AUC value for a proprietary expected goal model seems reasonable.
On January 11th, 2020, Scott Billeck asked Paul Maurice if Winnipeg’s proprietary expected goal model suggested Winnipeg’s play driving was as bad as the public models did. Here’s what Maurice had to say:
“No. No, it wouldn’t be. We would value…it wouldn’t be. Or positive. We’re not sitting here after 45 games and you’ve played well in three and the rest…that’s not the case. But in the games that we have an higher expected goals than the other team, it’s not nearly as extreme. It’s a far narrower band with all of it. We would like to think that what we do is get rid of all of the noise out of the analytics and get it down to valuable points.”
This quote is a bit of a word salad, but I dove in and read it a few times, and my interpretation is that Maurice basically said Winnipeg’s expected goal shares were still well below 50%, but not as atrocious as the public data suggests. And this isn’t a hard conclusion to reconcile; per Corey Sznajder’s work, Winnipeg was a team whose offense was built on the rush and counter-attacks, and the teams who play that way tend to have their play-driving capabilities underrated by public expected goal models.

This quote doesn’t tell us quite as much as the first one, but it makes it clear that Maurice was aware of his team’s struggles at 5-on-5 and respected data that he had seen which documented these struggles. It’s easy to get caught up in a straw man argument — even I’ve been guilty of this in the past — but Maurice was NOT telling us that Winnipeg’s proprietary expected goal model would flip everything on its head and say the Jets had done a great job of driving play. Rather, he just said that he preferred his data to the public data. And he should.
If we take Maurice’s first two quotes at face value and then compare and contrast them, we come to two reasonable conclusions: NHL teams have proprietary expected goal models that are roughly 5–9% better than public models, and while this improvement may shine a different light on certain teams, it isn’t going to flip everything on its head for a team like the Winnipeg Jets who were 2nd worst in 5-on-5 xGF% last season per my model. This information actually validates public models, and shows that despite the inaccuracy and shortcomings of the PBP data that public analysts work with, they still do a pretty good job of estimating the probability that a shot has of becoming a goal.
Just over one year and a pandemic later, when Maurice was asked about his captain Blake Wheeler’s struggles early in the season. This is when things got ugly and Maurice provided the quote you’re probably most familiar with:
“You’ll do your deep dives and your analytics and boy do they do a horses**** job of telling you what five guys do… I’m sensitive to it because I’ve been in awe of this guy since I got here. His work level, he’s unimpeachable in his character and how he runs that room and how he plays, he’s got 11 points in 10 games.”
This is a deflection, and frankly a bad faith argument. The criticisms were never about Wheeler’s work ethic, his character, or his point totals, but rather about his all around play at 5-on-5 and more specifically his defensive play. To bring up Wheeler’s point totals was never an attempt by Maurice to make a valid counter argument against anything that was said, but rather to deflect to the first thing that he could think of that would exonerate his captain. This is exactly what I’d want my boss to do for me in the face of public scrutiny, and it’s exactly what I’d do for my captain if I were in Maurice’s position.
While Maurice is clearly willing to approach this in good faith, divulge a lot of information and even admit his team as a whole is getting outplayed most nights, he’s understandably not happy when he’s asked to dive into the struggles of one player — specifically his captain, for whom he has much respect — and you can’t blame him for doing his best job to defend him. While I don’t entirely agree that public analytics do a horse shit job of telling you what five guys do, I can’t disagree that ten games into the season, there isn’t a metric out there available to the public that does a great job of it.
This isn’t to say Wheeler had been good through ten games — he probably had not played well — but the analytics on that ten game sample should have been taken with a much bigger grain of salt than they were. Maurice clarified his feelings on analytics the next day when Scott Billeck asked him if he felt analytics were taking away from the humanity of the game.
“No, because we’re full in on the analytics, right? I know that we spend like 16 hours a day and eight, nine months a year and then some in the summer, not just on analytics but on all parts of the game. But certainty in analytics we’ve got five full-time people here working on it. And so I take those guys, and that’s what they do for a living, and I put a bunch of coaches in a room and that’s what we all do for a living and we don’t come out with the confidence that I feel people do with analytics who do this kind of part time. And the quality of their shot data, which is a big driver in a lot — it’s not real good. So if I’ve got concerns about the questions that we’re asking our analytics department, and all the time we put into it, I’d like to think that maybe the people are pounding the table with it who are so darn sure that this analytics…this detail means so much, I would say maybe we should be a little bit more reserved in the strength of our opinion.”
A lot of things stand out here, but the first that I want to make note of real quick is that we know, straight from the source, that Winnipeg is full in on analytics, with a full -time staff of five people.
We should keep this in mind when we analyze charts like the one below provided by Shayna Goldman of The Athletic, which displays a list of the NHL’s publicly available analytical hires:
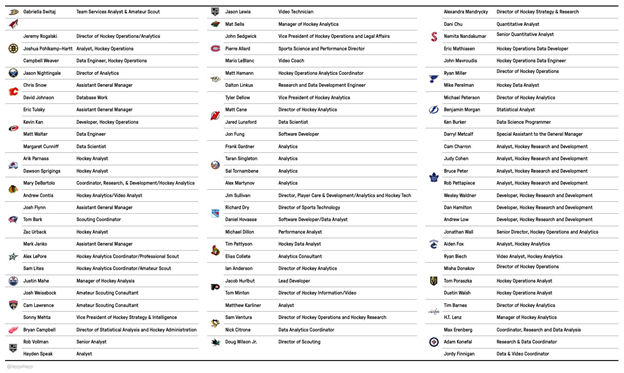
As you can see, the Winnipeg Jets, who we know have five full-time analytics employees, only have three members of their analytics team listed.
This chart is still a very valuable resource, and the fact that Winnipeg’s analytics team is under represented by it doesn’t automatically invalidate it or even mean the author made a mistake. What it does do, though, is show us that teams don’t generally list all of their analytical hires in one easy to find place that contains clear, concise job titles, and most teams likely have a larger analytics staff than they let on. Every team uses analytics, and even teams with poor 5-on-5 play-driving metrics like the Jets are “all-in” on analytics — some of them just brand it differently, so you should probably refrain from criticizing a team because they don’t have many names on one of these lists or praising a team because they have a lot.
My biggest takeaway from this, though, is that Maurice believes Winnipeg’s team of five full-time employees is less confident in their assertions than the fans and analysts in the public sphere are in theirs. This isn’t something I can hold up to scrutiny, since I’m not in the room with Winnipeg’s data team and listening to what they have to say. But the Dunning-Kruger effect, a proven cognitive bias, suggests this is likely the case:
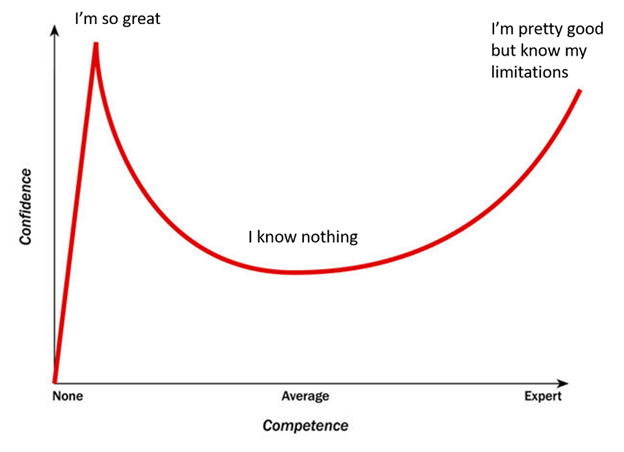
Chances are that Winnipeg’s data team who do this for a living and work closely with Maurice are a bit further to the right of this spectrum than the people Maurice finds himself arguing with. And I believe that if somebody made a Dunning-Kruger curve for hockey analytics, you’d see a smaller rise in confidence after average competence is reached than this chart depicts, because hockey is such a chaotic and unpredictable support with so many rapidly moving parts that it’s very difficult to make most conclusions with strong certainty.
There’s nothing wrong with being anywhere on this spectrum. Even the most introspective, self-aware, and intelligent people will have moments where they find themselves on the left side of it. I’m not berating anybody for being there, but I am offering a defense of Paul Maurice, who is understandably frustrated by people on the left side of the spectrum acting like they know more than the people on the right side with whom he works closely.
To give an example of hockey analytics fans failing to understand the limitations of model results and stating their opinions with far too much certainty, let’s take a look at Regularized Adjusted Plus-Minus (RAPM), a metric built through weighted ridge regression to isolate the impact of a hockey player on the rate at which team their does something. (Generally, the rate at which their team generates shots or expected goals.) I’m a huge fan of this metric, and I’ve even written a guide on how to build it, which includes source code.
As much as I love this metric, it’s also got a ton of limitations. It’s not hard to see the issues with regression analysis for NHL skaters: For example, if two skaters play 1,000 minutes together and 200 minutes apart from one another, the difference between them will be entirely quantified by the 200 minutes they played apart. I could go on and on about issues with RAPM, but instead I’ll refer to “Reframing RAPM” by Sam Forstner, an excellent article that has since been deleted. While I wish I could reference the article itself, I recall from memory the gist of it: Sam built an expected goal model and RAPM model, then used bootstrapping to determine the degree of uncertainty associated with the outputs of the RAPM model. He found that for the majority of players, you could not state with strong confidence that their impact was above or below average in a given season. And he did this using full seasons, which all contained between 1,082 and 1,270 total games played.
So, we’ve established that drawing hard conclusions about a player’s ability or even performance using RAPM in a full-season sample is problematic. Now imagine if the RAPM model was built on only 73 games played. Not per team, total. On January 24th, the outputs of such a model were released on Evolving-Hockey.com, both as numbers and in the form of the ever-popular RAPM bar graphs. While the modelers warned that the sample was small, that didn’t slow the tidal wave of charts that immediately swamped hockey Twitter, as visualizations of players with miniscule time on ice were wielded with strong certainty in arguments about how well they had played. Even stats-savvy individuals got caught up in the fun of new data being made available.
To give you an idea of the uncertainty associated with the data being shared, I ran my own RAPM model over this same 73 game sample, and the Lambda (a shrinkage parameter which determines how hard the outputs of the regression will be biased towards zero) I received through cross validation was fifteen times higher than the Lambda value I received for the 2018–2019 season when I ran the model. A different way of saying this is that the degree of uncertainty we should apply to this metric in this 73 game sample was 15 times higher than the degree we should apply to a full season. And remember, this metric already holds a good deal of uncertainty.
A great deal of this stems from a misunderstanding by the well-meaning enthusiasts of “stats Twitter” as to where the uncertainty of the model comes from. Many understandably interpreted “keep in mind that the sample is small” as meaning “we shouldn’t judge a player based on their performance in a small sample,” when in fact it meant “the model is so uncertain that we literally can’t measure the player’s performance in that sample.” So, even when you did see users of the data qualify their statements by saying things like “it’s early, but _” there was a clear disconnect between the certainty of their arguments and the extreme imprecision of the evidence itself.
I’ll acknowledge that I’m also guilty of not quantifying the uncertainty of the RAPM/WAR data I’ve put out. I’ve done my best to make it clear that those metrics have decent error associated with them and aren’t the be-all end-all, but that’s sort of a vapid statement without any real meat behind it. Going forward, I plan to do something similar to what Sam did with Reframing RAPM and quantify the uncertainty associated with these metrics.
Now, back to Winnipeg: I don’t know for certain what anybody on their data team is doing, but I highly doubt any of them are even wasting Paul Maurice’s time by sharing 73 games of RAPM with him at a point where almost any data scientist would agree the results are still nutty and not helpful. If they are, I’m extremely confident they’re doing a much better job of expressing the limitations associated with their results than hockey Twitter did when they got their hands on 73 games of RAPM. More likely, they’ve got superior metrics and they’re still applying far more uncertainty to those metrics than the public analytics crowd did.
I’ve spent the majority of this article talking about the strengths that proprietary analytics hold over public analytics, but I’d be remiss if I didn’t mention that there are also advantages that unbiased hockey fans using public analytics hold over team employees which make them less likely to be wrong about certain things. Consciously or unconsciously, team employees may feel pressure to find data that supports the pre-conceived notions of coaches and other executives, rather than challenge the beliefs they previously held and figure out who went wrong and where. This isn’t just some theory of mine; San Jose’s Head Video Coach Dan Darrow confirmed that this is how the Sharks use analytics:
This isn’t to say that every team uses analytics this way. I don’t know what the Winnipeg Jets do, but considering Paul Maurice acknowledged that their proprietary data showed their 5-on-5 play was lacking, it’s actually more than likely that they do not do this, or at least actively try to avoid and limit it. And in fairness to Dan Darrow and the San Jose Sharks, it’s also possible that they also don’t exclusively use analytics this way, or that he misspoke and his quote inaccurately described how they use analytics. But, the point still stands that there is a potential for certain cognitive biases to arise among NHL analytics teams that doesn’t exist with public analytics.
At the end of the day, we’re at our best when we acknowledge our strengths and weaknesses. The biggest strength of the public hockey analytics community is that we’re an open source repository full of smart people working together — not always directly, but always together — to be less wrong about hockey, and we’re not under pressure to confirm anybody’s pre-conceived notions. Our biggest weakness is that the data which most of our models are built on is notoriously inaccurate and lacks some key information, and that we’re trying to analyze a game that’s already wildly unpredictable and difficult to analyze to begin with.
By acknowledging our biggest strength, we can work together to make strong arguments against the usage of raw point totals at all situations as a metric to determine how well a player has played at 5-on-5, and explain why Maurice’s attempt to exonerate Wheeler’s poor play using point totals is mostly invalid. By acknowledging our biggest weakness, we can come together to figure out how much certainty we can apply to the metrics that we use — certainly more than we’ve currently applied — and then cool down a bit when criticizing or praising players based on metrics with a small sample size and a massive degree of uncertainty. By doing both, we stand to be wrong about hockey less frequently.
